另一天我的接收器为家庭音频设置完全死亡。Kaput。所以我出去拿到另一个,给出一个接收器的大小没有大于几个鞋盒的大小,我决定开车gt-r而不是带家庭庄园。我喜欢GT-R,因为这是巨大的乐趣,我每次开车时都会微笑,所以鉴于我的要求在GT-R的超级比例的能力津贴内,这是自然选择。
所以我带着微笑来到商店,找到了合适的接收器,然后我看到了一台电视。它不是很大,但对于卧室来说是完美的尺寸,卧室里仍然装饰着一台4:3的老式CRT设备,已经超过了它的黄金时期。我们谈判和捆绑两个单位的价格明智的工作相当好,并确保我的微笑仍然在地方。然后我试着把它们放进车里。
接收器不是问题,直接进入靴子。然而,电视是一个不同的故事。我试图将乘客座位一直向前移动,并将其倾斜,然后将电视堵塞进入背部两个小座位。没有快乐。我旋转盒子并尝试将它放在乘客座位上,但现在门不会关闭。我最终堵塞了司机座椅,这意味着我的6'5“框架几乎无法适合,我看不到后视镜。对于那些目睹现场的人来说,这一切都非常有趣,没有什么能通过看到有人试图将电视堵塞到它的背部的内部注意力的汽车的冷酷因素。
显然,gt-r糟透了,我应该摆脱它。是的,它会在3秒内得到100kph,沿300kph北方北方北方北方北方很不切实际。如果你想以巨大的速度执行最简单的任务,但任何复杂的(如携带电视),那就没关系了。这让我想到了这一点:
@troyhunt.我不是在开玩笑:)如果你以大规模的最简单的任务,但任何复杂的事情,那就没关系了。
——保罗·摩尔2015年5月24日
Paul和我就Azure Table Storage的优点(或不足之处,取决于您的位置)进行了一些讨论。关于这个存储构造的正确用例存在一些常见的误解,当然这是我之前多次讨论的话题,所以这是一个澄清事情的好机会。它可以是非常强大的,也可以是非常可怕的,这取决于你试图用它来做什么,这与早期GT-R运载能力的难题产生了共鸣。
我在过去几年中一直在使用表存储随着主要后端我被PWNED了吗?(HIBP)。目前,我在那里管理着近2亿行数据,每天经常为数百万个请求提供服务。这些请求几乎总是在50毫秒内执行,而实际的表存储查找本身可能只有4毫秒。这还不考虑负载——我从来没有看到过站点规模如此之大表存储成为一个瓶颈和正如我现在已经多次记录了,对于一个人创建和支持的网站来说,这通常是相当大的规模。
表存储之一![]() 我的优势是运行一个网站的“小家伙”是存储成本几乎免费的:
我的优势是运行一个网站的“小家伙”是存储成本几乎免费的:![]()

我按照16 GB的数据托管,我已经在Geo冗余存储上溅出,因此在那里每月拨打每月1.52美元。就这些。no - hand on - 我也必须支付交易费用:

上个月的账单表明,我的2500万不到2500万笔交易,这既是读写,这是另一个90c,对计算成绩也很重要。让我们慷慨,然后围绕它 - 例如,每月2美元和50℃,以常用于单位数毫秒衡量的速度,将几亿次记录存放了2500万次的历史记录。
啊,“但是等等”你说,“这是低效的”!
@scott_helme.@troyhunt.@azure.存储相同数据的多个副本;这是良好数据库设计的第一步。
——保罗·摩尔2015年5月24日
当然,这是对的,至少在表存储设计中我有大量的冗余。一个很好的例子就是我的储存方式贴所有关于粘贴的元数据存储在每个找到的电子邮件地址上吗.如果粘贴中有50k的电子邮件地址,那么我将拥有50k的粘贴名称,作者,日期,URL和其他完全冗余的数据。这是巨大的重复相同的数据,违背了良好数据库设计的第一步。这也是表存储的完美使用!
在过去,空间非常昂贵,计算能力有限,标准化提供了一种创建实体规范表示的方法,然后可以通过键从其他表引用这些实体。您将编写查询来将关系实体链接在一起,并经常以跨数据库的一系列连接结束。在大多数情况下,这是可以的,但在规模上,它会变得越来越困难,世界上所有棘手的索引都无法回避这样一个事实,即具有多个连接的数亿行会使工作变得困难。
使用像桌面存储等键值存储,您通常会从数据存储库中拉回单个记录。例如,每次搜索hibp时,请使用电子邮件域的分区密钥和别名的行密钥拉回记录。在上述示例中,记录的实际值是整个粘贴。此数据是“写一次,读取许多”,因为它永远不会改变。粘贴总是一个糊状,随着时间的推移不会改变这一点,所以它不需要一个规范记录,因为你在归一代的RDBMS中拥有。当然,它导致它导致的冗余存储是我需要支付的东西,这意味着我必须为每一个月找到额外的7C千兆字节数据我添加了。现代云规模和成本,这只是一个非问题。
现在我仍然在HIBP设计中使用SQL Azure数据库,因为坦率地说,它在某些方面比表存储做得更好。例如,我可以查询它使用TSQL这意味着能够寻找模式记录,更新大量数据在一个声明中,当我需要时,杠杆的好处一个正常化的数据结构定义的实体规范版本我可以随意改变。我为此付出了代价,提醒你
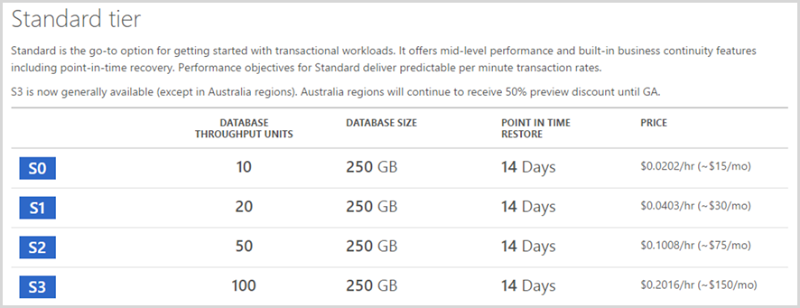
这比我现在为表存储支付的成本增加了六倍最便宜的“标准”数据库,这也是一个非常低的规格。我发现自己需要在S2级别运行一段时间,虽然是HIBP,这是我支付表存储的费用的三十次,但它只是在去标准化的模式之后,即我减少了足以使成本降低的架构。这是系统的大多数组件 - 您通常可以通过在它上投掷美元来增加我们的流行力。
这是课程的关键:您需要决定您的优化是什么,为此选择正确的存储构造。有时,与HIBP一样,甚至可能是NoSQL和SQL的混合动力。
表存储优化读取速度和成本。我的写作可能很慢正如我之前解释过的但这没关系,因为它是一个后台进程,不会影响用户体验。对我来说,重要的是人们搜索的速度快,而且我可以证明花费是合理的。
关系数据库优化了可查询性。我使用SQL Azure时,我想做的事情,如看到我的订阅者存在违反(我临时加载这个数据到SQL导入期间),以便我可以找出哪里有匹配。它非常擅长在数十万条记录中发现一条记录的出现,而这条记录也存在于包含数百万行的违规中。我也可以保持低性能和低成本因为这是一个后台过程。
NoSQL数据库不是您父亲的RDBMS,如果您试图这样使用它们,您将会非常失望,并倾向于宣布Azure是多么糟糕(或者其他云平台以低效的方式使用,我可能会补充说)的许多负面消息。但是,如果你想在关键字查找方面获得成本和性能方面的超级跑车,Azure Table Storage就是最好的选择。